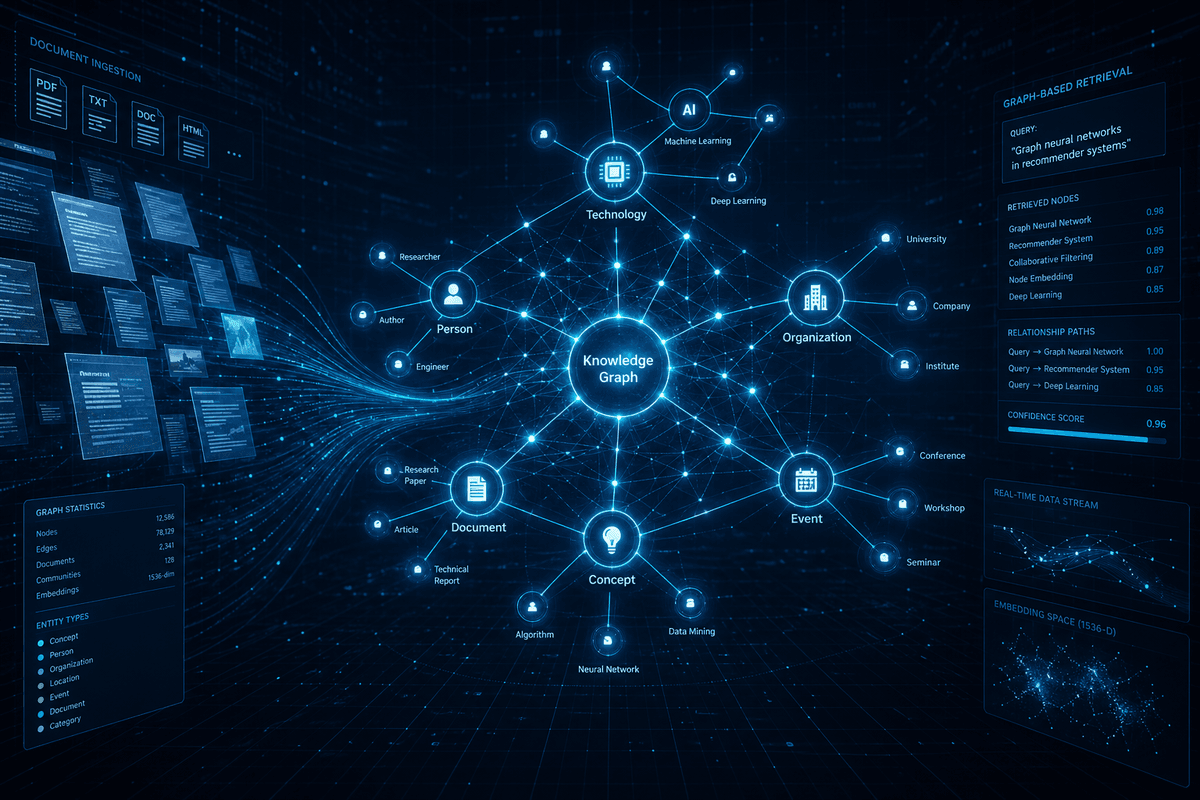
Retrieval-Augmented Generation (RAG) has become the default architecture for grounding LLMs in external knowledge. But most RAG systems still rely on flat vector search — treating documents as isolated chunks with no understanding of relationships between entities. LightRAG, a framework from the University of Hong Kong published at EMNLP 2025 Findings, offers a fundamentally different approach: graph-structured indexing with dual-level retrieval1.
With 34,000+ GitHub stars and 250 contributors2, LightRAG has become one of the most popular open-source RAG frameworks. The question is whether it deserves the hype.
What Makes LightRAG Different
Traditional RAG systems like LangChain’s default retriever or LlamaIndex use vector similarity search — embedding document chunks and finding the closest matches to a query. This works well for simple factual lookups but fails when questions require understanding relationships between entities1.
LightRAG takes a different approach. During indexing, it extracts entities and relationships from documents, building a knowledge graph. During retrieval, it uses a dual-level strategy1:
- Low-level retrieval: Focuses on specific entities and their immediate relationships — useful for precise factual queries
- High-level retrieval: Surfaces broader topics and themes — useful for analytical or exploratory questions
The integration of graph structures with vector representations enables efficient retrieval of related entities and their relationships, significantly improving response times while maintaining contextual relevance1.
Benchmark Results: LightRAG vs. The Field
The LightRAG team evaluated their framework against four baselines across four domains: agriculture, computer science, legal, and mixed2.
Table 1: Overall Performance Comparison 2
| System | Agriculture | CS | Legal | Mix |
|---|---|---|---|---|
| NaiveRAG | 32.4% | 38.8% | 15.2% | 40.0% |
| LightRAG | 67.6% | 61.2% | 84.8% | 60.0% |
| RQ-RAG | 32.4% | 38.0% | 14.4% | 40.0% |
| LightRAG | 67.6% | 62.0% | 85.6% | 60.0% |
| HyDE | 26.0% | 41.6% | 26.8% | 40.4% |
| LightRAG | 74.0% | 58.4% | 73.2% | 59.6% |
| GraphRAG | 45.6% | 48.4% | 48.4% | 50.4% |
| LightRAG | 54.4% | 51.6% | 51.6% | 49.6% |
The results are striking. LightRAG outperforms NaiveRAG by 35+ percentage points on the agriculture and legal domains. Against GraphRAG — Microsoft’s graph-based RAG framework — LightRAG wins on three of four domains, with the legal domain showing the most dramatic gap (51.6% vs. 48.4%)2.
The Technical Architecture
LightRAG’s architecture has three core components1:
1. Graph-Based Text Indexing
Unlike traditional RAG systems that store documents as flat text chunks, LightRAG extracts entities and relationships during indexing, constructing a knowledge graph. This enables the system to understand how concepts relate to each other — not just what they are.
2. Dual-Level Retrieval
The retrieval system operates at two levels:
- Entity-level: Finds specific entities and their direct relationships
- Topic-level: Identifies broader themes and patterns across the knowledge graph
This dual approach allows LightRAG to handle both precise factual queries (“What is the capital of France?”) and analytical questions (“How has France’s relationship with the EU evolved?“).
3. Incremental Updates
LightRAG includes an incremental update algorithm that allows new data to be integrated without rebuilding the entire index. This is critical for production systems where data is constantly changing1.
Practical Considerations
LightRAG supports multiple LLM providers including OpenAI, Ollama, Azure, Gemini, and HuggingFace2. It also supports various embedding models and can integrate with reranking systems.
The framework is written primarily in Python (81.2%) with TypeScript components (12.9%)2. It’s MIT-licensed and actively maintained, with 70 releases and the latest version (v1.4.15) released on April 19, 20262.
When to Use LightRAG
LightRAG is most valuable when1:
- Your queries require understanding relationships between entities
- You need to process documents that reference each other
- You want a system that can incrementally update without full reindexing
- You’re working with domains where context and relationships matter (legal, research, technical documentation)
For simple factual lookups (e.g., “What’s the weather in Tokyo?”), traditional vector-based RAG may still be sufficient and faster.
Limitations
The benchmark comparison with GraphRAG is closer than with other baselines, suggesting that graph-based approaches have diminishing returns compared to simpler methods. Additionally, LightRAG’s graph construction adds overhead during indexing — the trade-off is faster and more accurate retrieval at query time.
The legal domain results are particularly interesting: LightRAG’s 84.8% vs. NaiveRAG’s 15.2% suggests that for complex, relationship-heavy domains, graph-based RAG isn’t just better — it’s essential2.
Bottom Line
LightRAG represents a significant step forward for RAG systems. By combining graph-structured indexing with dual-level retrieval, it addresses the fundamental limitation of traditional RAG: the inability to understand relationships between entities. With 34K+ GitHub stars and publication at EMNLP 2025, it’s become the de facto standard for graph-based RAG.
For teams building RAG systems on complex, relationship-heavy data, LightRAG is worth serious consideration. The benchmarks show clear advantages over both traditional and graph-based alternatives, and the incremental update capability makes it practical for production use.
References
Footnotes
-
LightRAG: Simple and Fast Retrieval-Augmented Generation — EMNLP 2025 Findings paper by Guo et al. (HKU), describing the graph-based indexing and dual-level retrieval architecture https://aclanthology.org/2025.findings-emnlp.568/ ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7
-
HKUDS/LightRAG GitHub Repository — 34K+ stars, benchmark results comparing LightRAG against NaiveRAG, RQ-RAG, HyDE, and GraphRAG across four domains https://github.com/HKUDS/LightRAG ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8